ll st[MAXN << 2], add[MAXN << 2]; //线段树和标记 int n, N = 1; //n为原始数据数量,N为**原始数据的起始位置**
inlinevoidbuild() { for (; N < n + 1; N <<= 1); //找到原始数据应该在的位置 for (int i = N + 1; i <= N + n; i++) read(st[i]); //放置原始数据 for (int i = N - 1; i >= 1; i--) st[i] = st[i << 1] + st[i << 1 | 1];//从下向上构建线段树 }
代码量变小了,意味着信息浓度的增加。这短短三个for语句其实蕴含了不少信息量。
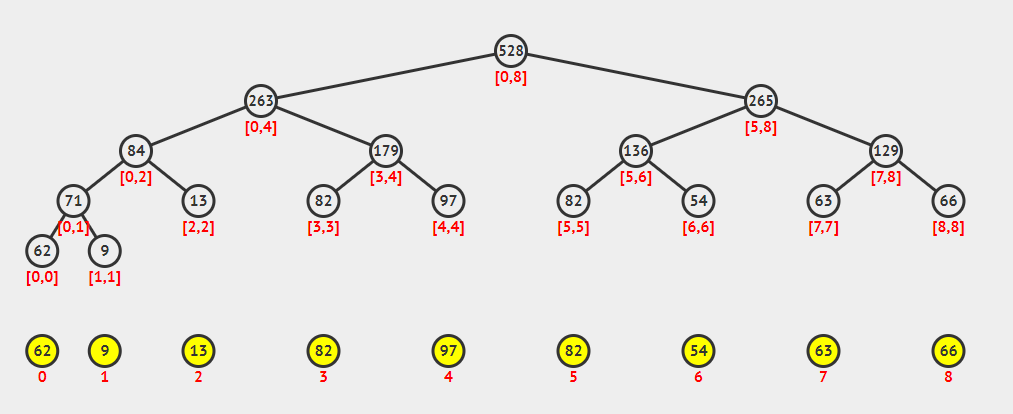
在zkw线段树中,我们将原始数据放在线段树数组的最后方+1的位置,这样将有利于之后的各种操作。
二叉树中,对于节点n,n / 2 和 n / 2 + 1分别是n的两个儿子节点。位运算中的表述如上代码,不再赘述。
inline ll query(int l, int r) { int s = N + l - 1, t = N + r + 1; //s节点和t节点 //lNum表示当前s包含的标记个数,rNum表示当t包含的标记个数 //num表示当前层的节点包含的标记个数(从1开始) ll lNum = 0, rNum = 0, num = 1, ans = 0;
//如果s和t拥有同一个父亲节点,那么s ^ t == 1,即二进制路径只有最后一位不同 //那么s ^ t ^ 1 == 0,循环停止 //每个循环节,s和t上移,num右移一位 for (; s ^ t ^ 1; s >>= 1, t >>= 1, num <<= 1) { if (add[s]) ans += add[s] * lNum; //处理标记 if (add[t]) ans += add[t] * rNum; if (~s & 1) {ans += st[s ^ 1]; lNum += num;} if ( t & 1) {ans += st[t ^ 1]; rNum += num;} //如果s是父亲的左儿子,二进制最后一位应该是0,取反后&1应该是1 //同理,t是父亲的右儿子时,t & 1应该是是1 } for (; s; s >>= 1, t >>= 1) //继续上推到根节点 { ans += add[s] * lNum; ans += add[t] * rNum; } return ans; }
inlinevoidupdate(int l, int r, ll k) { int s = N + l - 1, t = N + r + 1; ll lNum = 0, rNum = 0, num = 1; for (; s ^ t ^ 1; s >>= 1, t >>= 1, num <<= 1) { st[s] += k * lNum; //更新自己 st[t] += k * rNum; //满足条件就更新自己的兄弟 if (~s & 1) {add[s ^ 1] += k; st[s ^ 1] += k * num; lNum += num;} if ( t & 1) {add[t ^ 1] += k; st[t ^ 1] += k * num; rNum += num;} } for (; s; s >>= 1, t >>= 1) //上推到根节点 { st[s] += k * lNum; st[t] += k * rNum; } }